
I received my master’s degree at Tsinghua University under the supervision of Prof. Xiu Li. in 2025 and obtained my bachelor’s degree at Xidian University in 2022. I was awarded Outstanding Graduate in both my undergraduate and graduate studies.
Recently, I focus on multimodal learning (multimodal large language model, multimodal pre-training) and large language model. Prior to that, I worked primarily on basic computer vision (object detection, image assessment, video segmentation).
I have interned at Baidu NLP Group (ERNIE), Tencent Youtu Lab, DJI Automotive Perception Group, Tencent AIGC Group, etc.
🔥 News
- [2025.07] One paper about generic image quality assessment is accepted by ACMMM 2025.
- [2025.06] I received the honor of “Outstanding Graduate of Tsinghua University” (Top 1%).
- [2025.03] One paper about underwater acoustic learning is accepted by Pattern Recognition.
- [2024.07] One paper about multimodal learning is accepted by ECCV 2024.
- [2024.05] I join Baidu ERNIE, working on multimodal large language models.
- [2024.05] One paper about object detection is accepted by IEEE TNNLS.
- [2024.03] One paper about video segmentation is accepted by ICME 2024.
- [2024.03] I join Tencent Youtu, working on multimodal large language models.
- [2023.10] I join DJI Automotive, working on multimodal pre-training for autonomous driving.
- [2023.08] One paper about defect detection is accepted by IEEE TIM.
- [2023.03] I join Tencent, working on AIGC model pre-training.
📝 Publications
Multimodal Learning
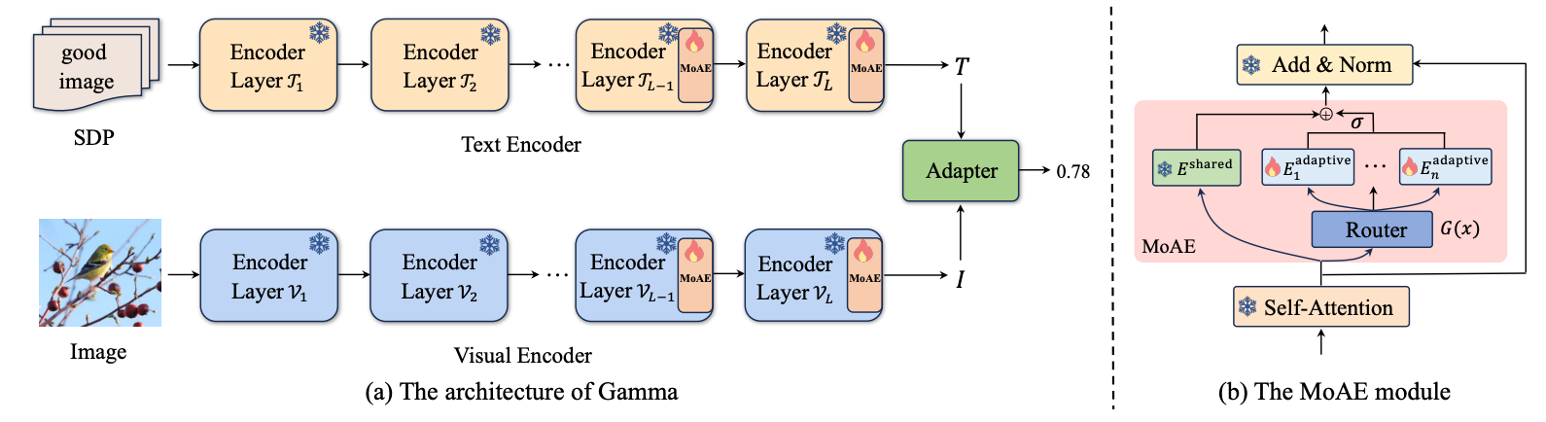
Gamma: Toward Generic Image Assessment with Mixture of Assessment Experts
Hantao Zhou, Rui Yang, Longxiang Tang, Guanyi Qin, Runze Hu, Xiu Li
ACM Multimedia (ACM MM), 2025
- Gamma is a general image assessment model that can be applied to natural image, underwater image, AIGC image and face image assessment, etc.
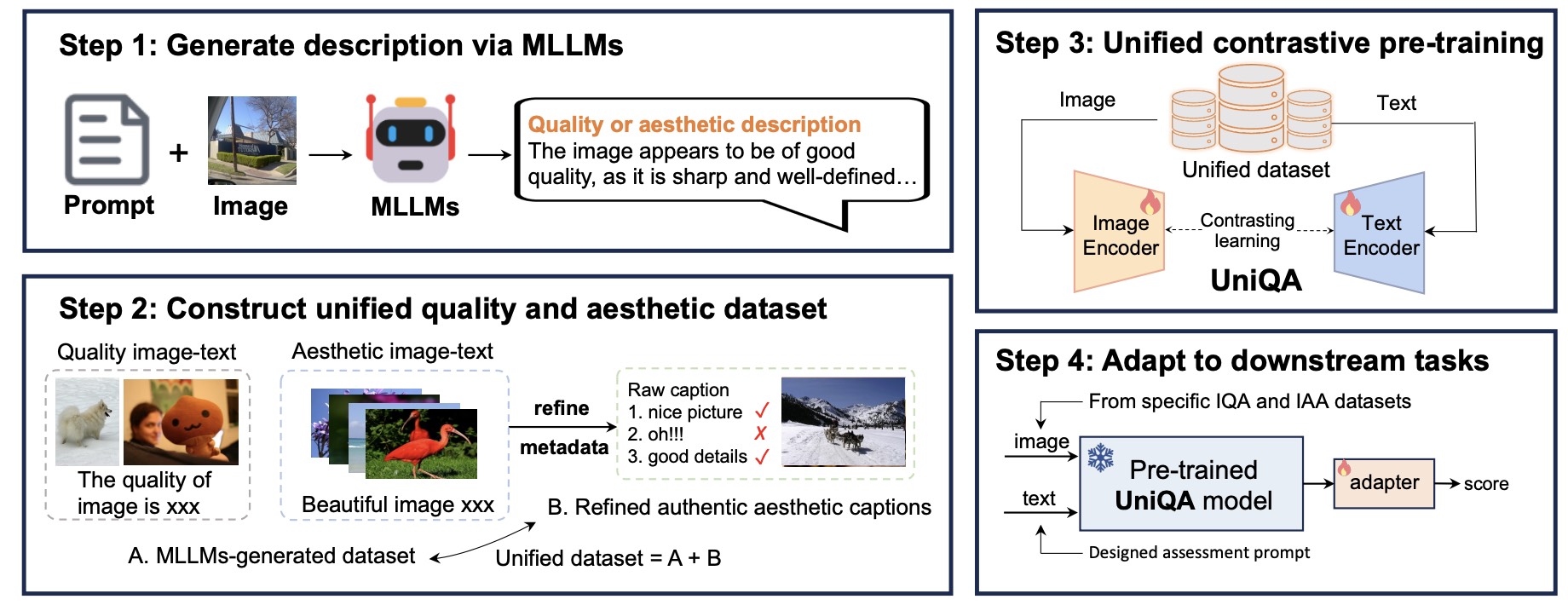
UniQA: Unified Vision-Language Pre-training for Image Quality and Aesthetic Assessment
Hantao Zhou, Longxiang Tang, Rui Yang, Guanyi Qin, Yan Zhang, Runze Hu, Xiu Li
- UniQA is a foundational multimodal image assessment model that supports image quality and aesthetic assessment tasks and generalizes well to natural images, AIGC images, and medical images, etc.
- We generate multimodal dataset via multimodal large language model and pretrain CLIP on authentic and synthetic data.
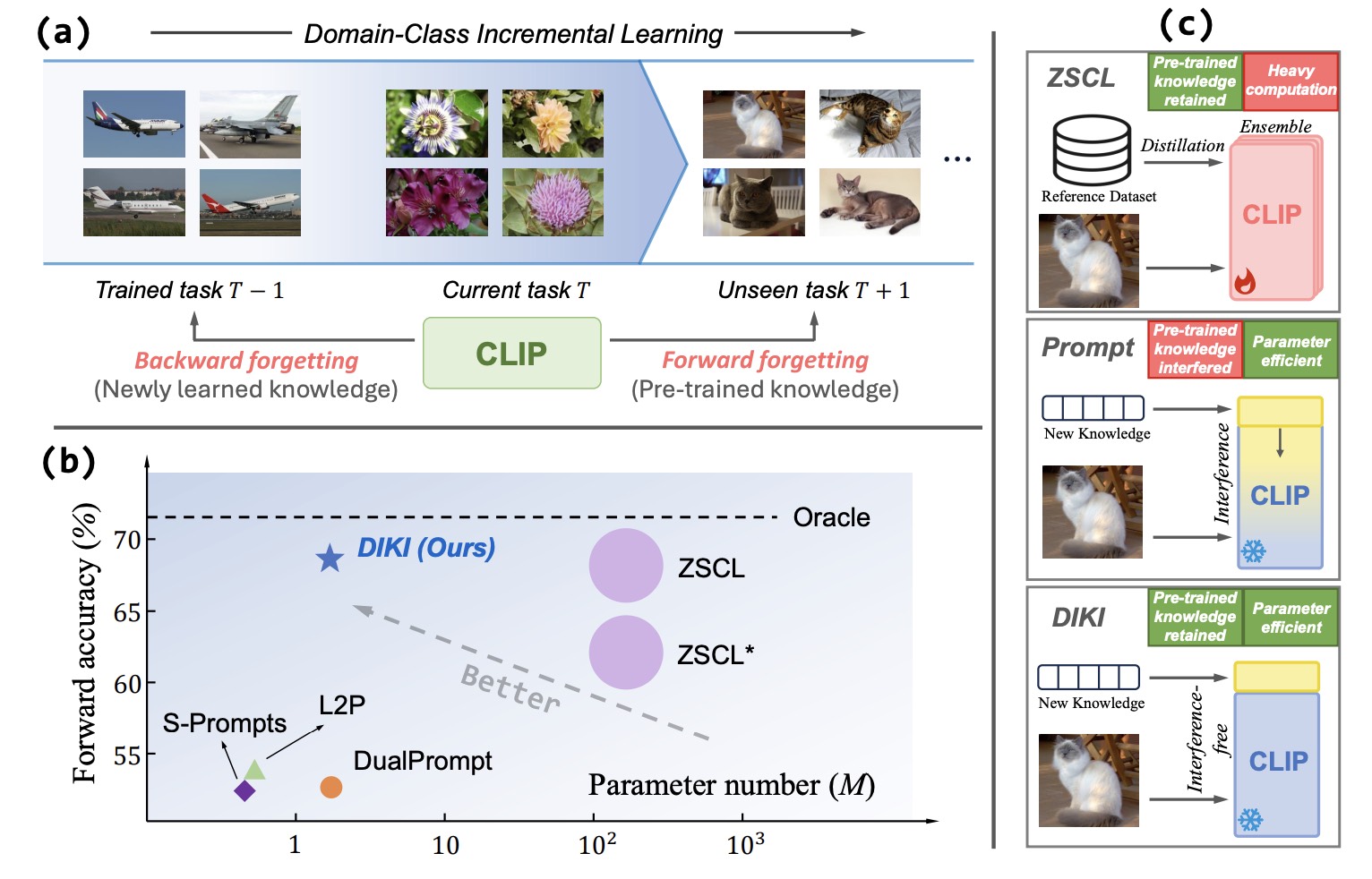
Mind the Interference: Retaining Pre-trained Knowledge in Parameter Efficient Continual Learning of Vision-Language Models
Longxiang Tang, Zhuotao Tian, Kai Li, Chunming He, Hantao Zhou, Hengshuang Zhao, Xiu Li, Jiaya Jia
European Conference on Computer Vision (ECCV), 2024
- We propose the Distributionaware Interference-free Knowledge Integration (DIKI) framework to retain pre-trained knowledge of in continual learning of Vision-Language Models (VLMs).
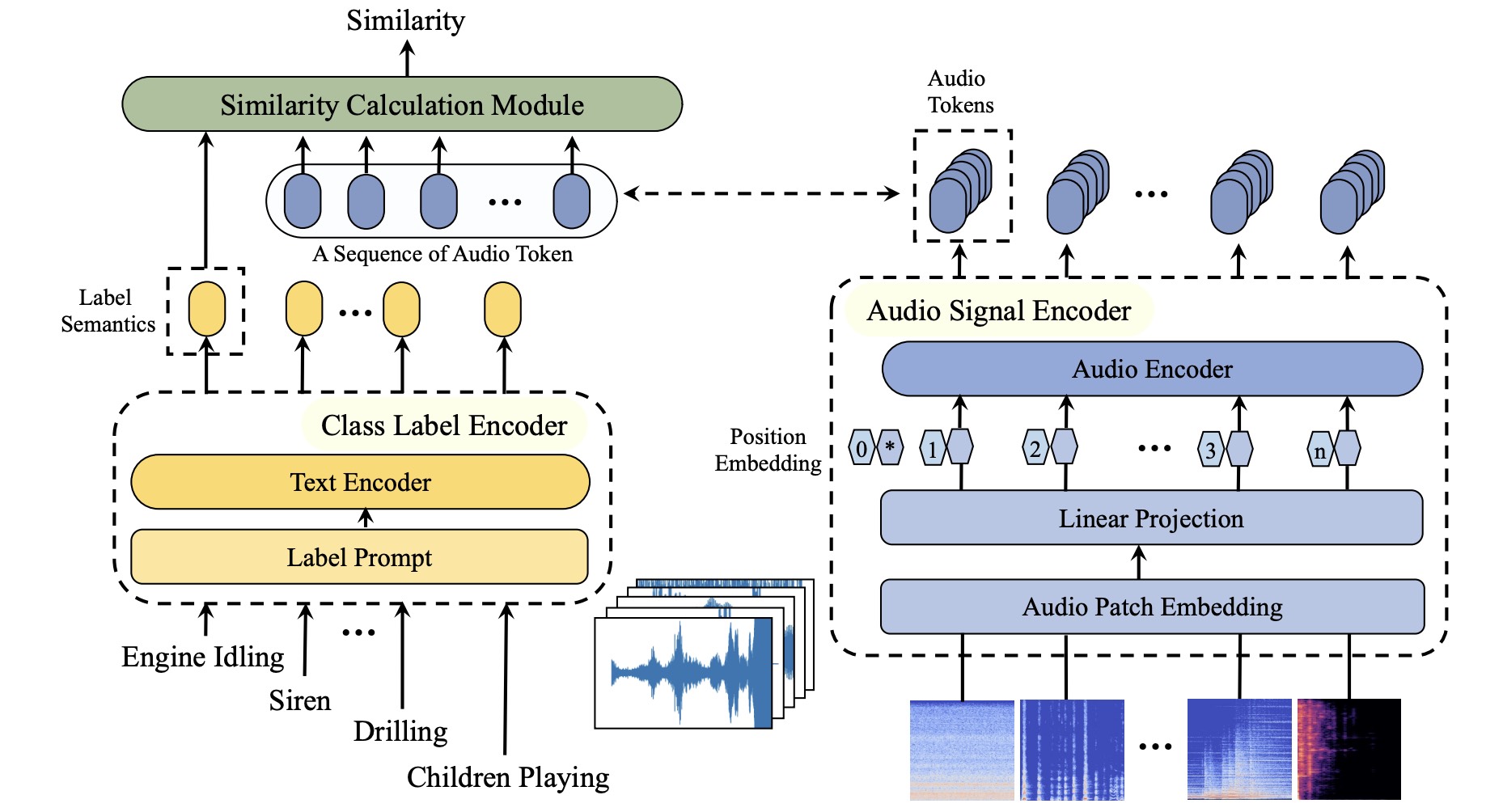
SemanticAC: Semantics-Assisted Framework for Audio Classification
Yicheng Xiao, Yue Ma, Shuyan Li, Hantao Zhou, Ran Liao, Xiu Li
International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023
- We propose SemanticAC, a semantics-assisted framework for Audio Classification to better leverage the semantic information.
Detection and Segmentation
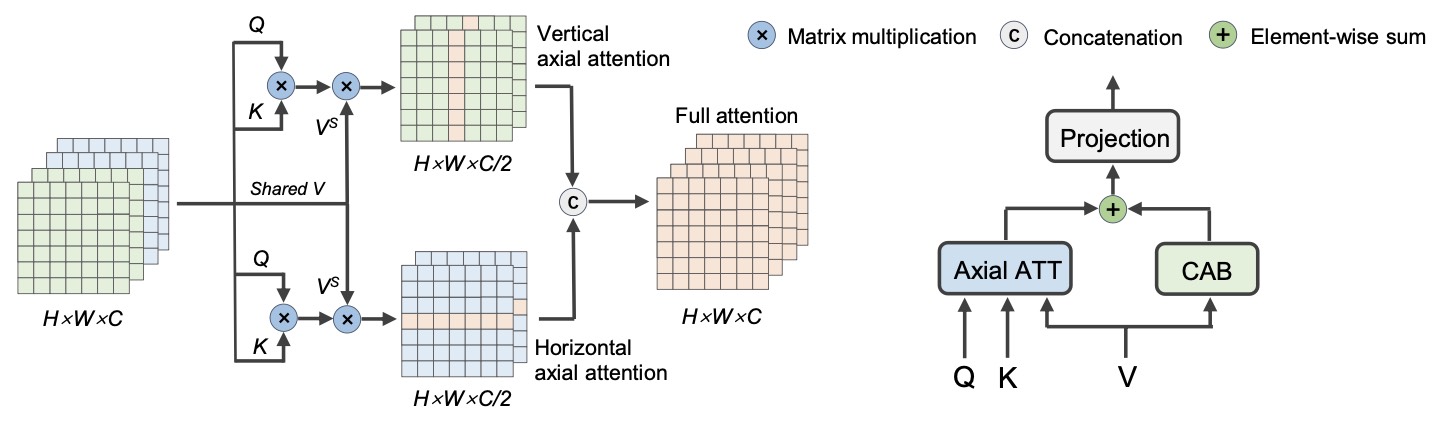
UniHead: Unifying Multi-Perception for Detection Heads
Hantao Zhou, Rui Yang, Yachao Zhang, Haoran Duan, Yawen Huang, Runze Hu, Xiu Li, Yefeng Zheng
IEEE Transactions on Neural Networks and Learning Systems (IEEE TNNLS), 2024
- UniHead unifies various perceptions in a single detection head via novel attention modules, which can enhance the performance of many classical detectors on both object detection and segmentation tasks.
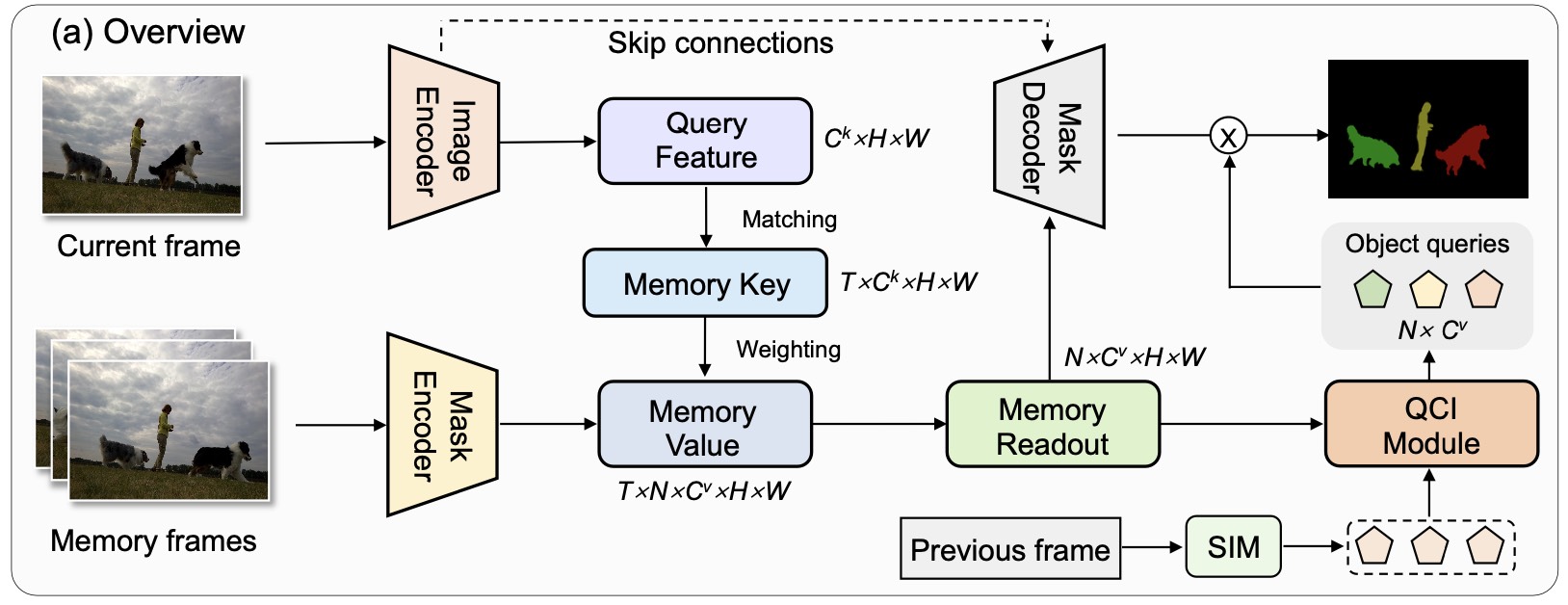
Video Object Segmentation with Dynamic Query Modulation
Hantao Zhou, Runze Hu, Xiu Li
International Conference on Multimedia and Expo (ICME), 2024
- We design a dynamic query modulation framework for Video Object Segmentation, which can update queries and perform multi-object interaction effectively.
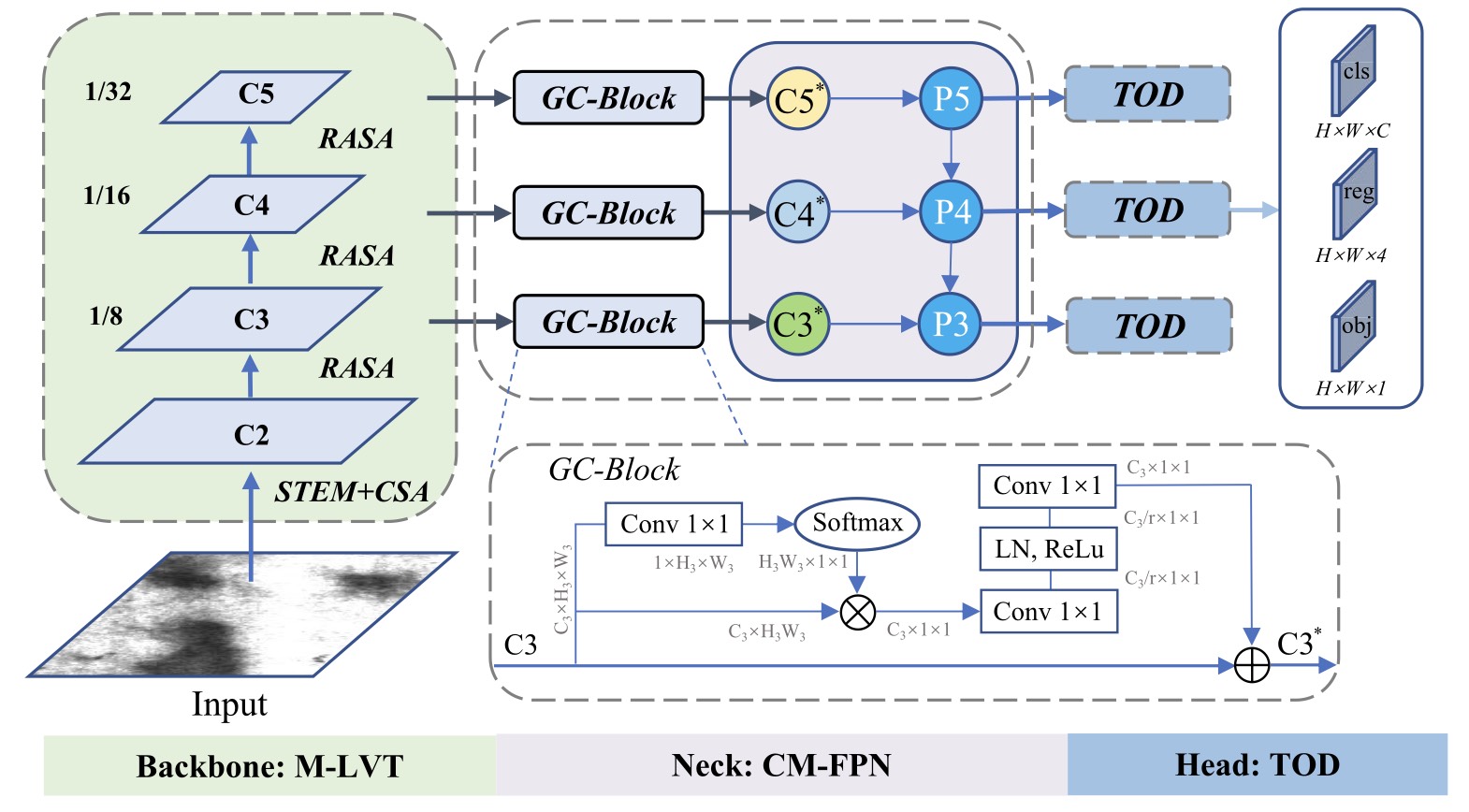
ETDNet: Efficient Transformer-Based Detection Network for Surface Defect Detection
Hantao Zhou, Rui Yang, Runze Hu, Chang Shu, Xiaochu Tang, Xiu Li
IEEE Transactions on Instrumentation and Measurement (IEEE TIM), 2022
- We propose the Efficient Transformer-Based Detection Network (ETDNet) for defect detection, which includes variety of novel Transformer-based module designs to improve the detection performance.
Patent:
- 用于图像质量和美学评价的统一视觉语言模型预训练和调整方法 , 李秀, 周涵涛
🎖 Honors and Awards
- [2025.06] Outstanding Graduate of Tsinghua University (Top 1%)
- [2024.10] 1st Class Scholarship at Tsinghua University (Top 5%)
- [2023.10] 1st Class Scholarship at Tsinghua Shenzhen International Graduate School
- [2022.05] Outstanding Graduates of Shaanxi Province (Top 1%)
- [2021.12] National Scholarship, Xidian University (Top 1%)
- [2020.12] National Scholarship, Xidian University (Top 1%)
📠 Academic Services
Conference Reviewer: ICLR (2024), ACMMM (2023-25), ICME (2024-25)
Journal Reviewer: International Journal of Computer Vision (IJCV)
📖 Educations
- 2022.09 - 2025.06, Master, Tsinghua University, Shenzhen.
- 2018.09 - 2022.06, Bachelor, Xidian University, Xian.
💻 Internships

- Topic: Multimodal Large Language Model Pre-training
- Job Description: I develop Multimodal Large Language Model (MLLM) for ERNIE Bot. Specifically, I focus on video MLLM pre-training, involving video, image, audio, and language modalities.

- Topic: Multimodal Large Language Model Pre-training
- Job Description: I work on Multimodal Large Language Model based on discrete coding.

- Topic: Multimodal Image-Text Pre-training
- Job Description: I develop a image-text retrieval system for DJI Automotive. Specifically, I construct a traffic image-text dataset and enhance the existing multimodal model's performance on traffic scene using traffic image-text pre-traing. I also leverage LLM (Large Language Model) and Diffusion Model to generate synthetic data to further enhance the model's performance.

- Topic: Text to Image Generation (AIGC)
- Job Description: I employed various techniques to improve the performance of the AIGC model, such as image aesthetics assessment and human keypoint detection.
Thanks so much for RayeRen’s open-sourced template version AcadHomepage 